Ontology Overview
A scalable, flexible and extensible AI ecosystem must support decentralisation, security, interoperability, and accessibility features. Creating such robustness requires that all major components of the system "should speak the same language", which can be achieved by the use of an ontology-based protocol.
By using this model, AI innovators can define the format of the inputs and outputs of the algorithms, allowing automatic validation of the provided data and cross AI interoperability. Based on their input/output definition, multiple AI instances can be combined into execution pipes. Compared to traditional applications, AI algorithms possess some special requirements related to storing the data needed for testing, training and execution. These requirements can be fulfilled by storing data using an ontology-based format so AI algorithms can use the information without additional processing.
Establishing a standard format will increase the number of AI algorithms that can use the same data sets and the possibilities of combinations.
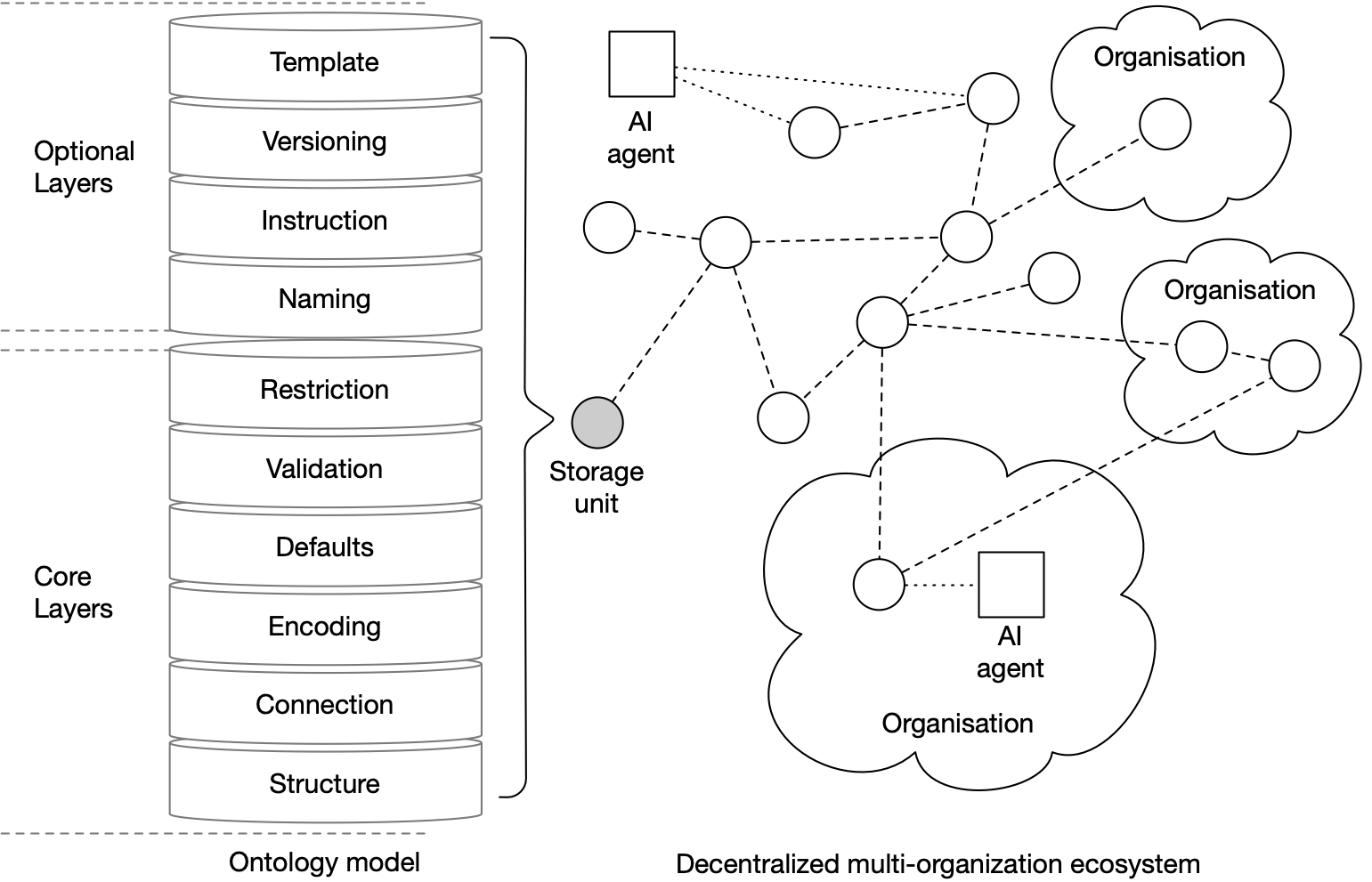
Fig.1: Ontology high-level architecture
Ontology architecture
From a high-level perspective, the architecture is composed of the following layers:
| Name | Description |
|---|---|
| Structural layer | the formal specification of an ontology in its purest form, composed of classifications, concepts, properties and relations |
| Connection layer | contains information about a concept’s location, be it internal or external, as well as mappings between multiple versions of the same ontology |
| Encoding layer | specifies the encoding format, such as UTF-8, ISO or any format |
| Defaults layer | used for defining the fallback values for specific properties |
| Validation layer | specifies formal validation rules on individual schema properties |
| Restriction layer | contains a set of contextual restrictions based on schema properties |
| Naming layer | tags schema elements in human-readable format |
| Instruction layer | guides users on how to provide the input data and offer recommendations on the layout's appearance. |
| Versioning layer | contains community proposals about schema structure changes and future evolution |
| Template layer | used for contextual partitioning of the schema elements |
