Ontology-based data integration
The heterogeneous format of the data represents the top impediment in creating a genuinely interoperable crossorganization system. Developing a common data format to act as a universal language represents one of the largest challenges that needs to be addressed in order to create a truly interconnected and interoperable ecosystem.
A. Data Format
Based on [61], Openfabric utilizes a protocol composed of interoperable ontology models [62], [63] representing the input and output of the AI agents. Although each organization has its semantics, context, and perception of the data, this protocol will act as a translator/abstractor fostering internal and external collaborations. As depicted in Fig. 6, the model proposes a layered architecture in which each layer is composed of machine-readable semantic data structures that provide context on a particular dimension of the ontology concepts. The most important aspect of this approach is that data structures can be used, deployed, and updated in a decentralized manner. The core layers are designed to store machine-targeted semantic information. The optional layers provide humanreadable information in the communication between agents, but are compelling in cases which involve human-computer interactions. From a high-level perspective, the architecture is composed of the following layers:
Structural layer - the formal specification of the ontology in its purest form, composed of concepts, properties, and relations;
- Connection layer - contains information about the location of concepts from external ontologies and mappings between multiple versions of the same ontology;
- Encoding layer - specifies the used encoding format, like UTF-8, ISO, or any other chosen format;
- Defaults layer - used to define the fallback values for specific properties;
- Validation layer - used to add formal validation rules for schema properties;
- Restriction layer - contains a set of contextual restrictions between schema properties;
- Naming layer - tags schema properties classes and relations in human-readable format;
- Instruction layer - includes guidance information on how the user should provide the input data;
- Versioning layer - contains community proposals about schema structure changes and future evolution;
- Template layer - used for the contextual fragmentation of the schema.
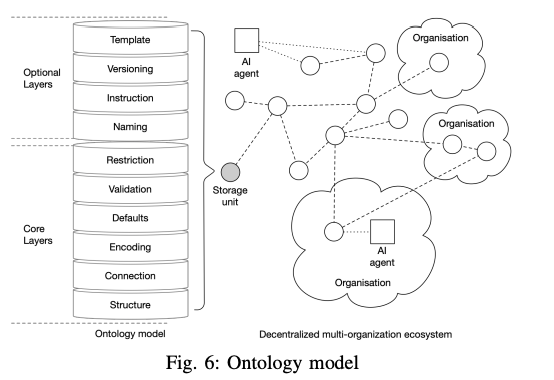
Fig. 6: Ontology model
B. Compatibility and Versioning
Efficient ontologies need to be plastic, subject to constant change and improvement, but at the same time, they also need to be sufficiently stable for consistent communication. The current architecture [61] ensures the plasticity and stability of the structure by using versioning and property mapping mechanisms. Further, the formal model of the transformations and the specific characteristics are defined from a mathematical perspective. Considering the following notations:
- property with definition domain on version
- property with definition domain on version
- from a temporal perspective
- is the forward transformation and is the backwards transformation
mapping can be defined as
Depending on the evolution of the domain between versions X and Y, the following cases emerge:
- and no loss of information between versions and then is called a stable mapping, noted as ;
- and there is a loss of information on the backward transformation between versions and then is called a forward-stable mapping noted, as ;
- and there is a loss of information on the forward transformation between versions and then is called a backwards-stable mapping, noted as .
Considering as the set of all mappings between versions and , the information between versions may be transported bidirectionally with ease when Even though in practice implementing a full set of stable mappings is a difficult task, it provides an excellent, ideal goal to aim for. Of course, the ideal case presented above is unlikely to be found in practical cases, which is why the case of partially-stable mappings is closer to reality:
-
partially backwards stable
-
partially forward stable
Information might be lost in the partial stability cases, which is why it is necessary to consider a contextual and gradual approach that is tailored to a domain's specific needs.
C. Algorithm Composition
Aside from the formal definition of data structures, allowing cross-organization interoperability, the model presents a more subtle - but strikingly powerful - feature. The consistency and uniformity achieved by ontology models [61] facilitate integration by providing a clear data-contract at the algorithm boundaries (input and output). This feature opens up new possibilities for creating smarter solutions which combine the functionalities implemented by existing algorithms. As depicted in Fig. 7, the proposed mechanism uses gRPC [64] stubs to allow remote AI invocation and ontology concepts to ensure communication and data consistency. The presented architecture enables incorporating functionality from multiple AIs with custom logic blocks. From the development standpoint, this will be perceived as including an external library. The Openfabric toolkit will generate all the boilerplate required to perform the integration.
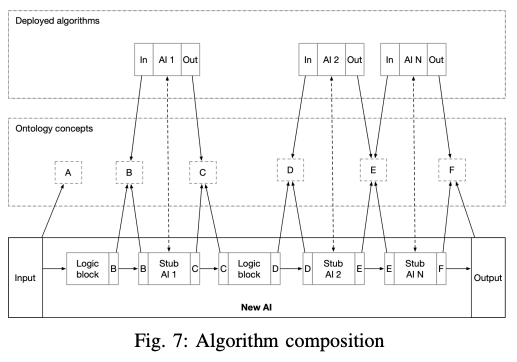
Fig. 7: Algorithm composition
